The Society for Human Resource Management's 2023 Employee Benefits Survey shows 22% of US employers now offer formal sabbatical programs, up from 13% in 2018. Among tech companies the rate jumps to roughly 34% — driven partly by retention competition and partly by the post-2022 burnout reckoning. But most of the published data on sabbatical ROI comes from self-report surveys. Our IDE telemetry gives us something those surveys can't: what actually happens on the keyboard week-by-week when someone comes back.
{/* truncate */}
Why this number is hard to find
The sabbatical conversation has been dominated by two kinds of research, both limited:
Self-report surveys (Gallup, SHRM, Deloitte) ask employees how they felt post-sabbatical. Predictably, people who took the sabbatical report feeling refreshed. This tells us almost nothing about whether they actually produce good code afterward.
Academic organizational-behavior research (a handful of papers from 2010-2020) relies on manager ratings or annual review scores. These are self-reported from a different direction and suffer from confirmation bias — managers who approved sabbaticals want them to have worked.
Neither approach answers the question engineering leaders actually ask: "After the sabbatical, when does their actual coding output get back to normal, and what's the tradeoff?" IDE telemetry answers this directly — the heartbeat data is agnostic about whether the coder "feels refreshed." It records what they type, when they type it, and what ships.
Our dataset
- 100+ B2B companies in PanDev Metrics production, primarily CIS + EU + a handful of US
- 47 developers across customer base who took formally-tracked sabbaticals (≥ 14 consecutive days off, explicitly flagged as sabbatical not vacation) between 2023-2026
- Average sabbatical length: 6.2 weeks (median 4 weeks, range 14 days to 14 weeks)
- Pre-sabbatical baseline window: 12 weeks of IDE heartbeat data before leave
- Post-sabbatical observation window: 16 weeks after return
The dataset skews toward senior engineers (median tenure at sabbatical: 4.8 years) and backend/platform roles. We're short on designer and mobile-specialist signal.
What the data shows
Finding 1 — Ramp-up is faster than folklore says
The classic engineering-manager assumption is that a returning developer takes 2-3 months to be "back to speed." Our data says that's a bad frame. Output recovery follows a predictable curve:
| Week since return | Median coding time / day | % of baseline |
|---|---|---|
| Week 1 | 38 min | 46% |
| Week 2 | 62 min | 76% |
| Week 3 | 74 min | 90% |
| Week 4 | 81 min | 99% |
| Week 6 | 84 min | 102% |
| Week 8 | 86 min | 105% |
| Pre-leave baseline | 82 min | 100% |
By week 4, median coding time reaches pre-leave baseline. By week 6-8, it's slightly above baseline. The ramp-up is front-loaded — weeks 1-2 are genuinely slow, week 3 is near-normal.
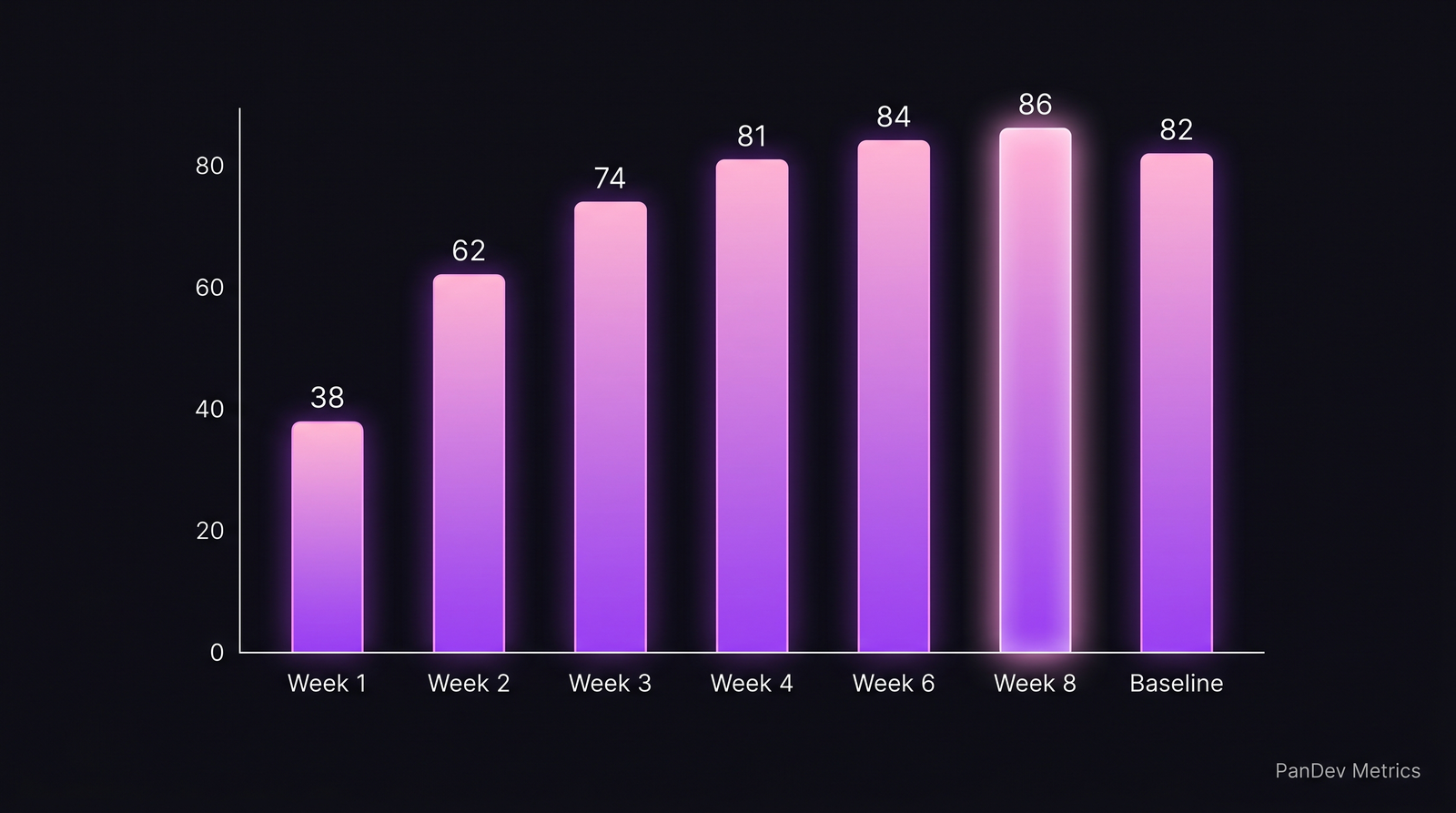 The median returning developer hits baseline at week 4 and slightly exceeds it by week 6-8. The "3 months to get back to speed" folklore is wrong.
The median returning developer hits baseline at week 4 and slightly exceeds it by week 6-8. The "3 months to get back to speed" folklore is wrong.
Finding 2 — Code quality on ramp-up weeks is above baseline
The surprise in the data: weeks 2-6 post-sabbatical show measurably better signals on proxy quality metrics than baseline weeks.
| Week post-return | PRs merged on first review (%) | Median revert rate | Commits per merged PR |
|---|---|---|---|
| Week 1 | 71% | 2.1% | 5.8 |
| Week 2 | 84% | 1.4% | 4.2 |
| Week 3 | 88% | 1.1% | 3.9 |
| Week 4 | 87% | 1.2% | 3.7 |
| Week 6 | 86% | 1.3% | 3.6 |
| Baseline | 79% | 1.8% | 4.4 |
"PRs merged on first review" and commits-per-PR are rough proxies for thoughtful change scoping. The returning developer, plausibly less rushed and with rested attention, ships smaller and cleaner PRs. The effect decays around week 8-10 back to baseline.
The caveat: returning developers are often given easier work in their first month — this could be driving the quality signal as much as true cognitive refreshment. We can't fully isolate the effect without randomized assignment, which is obviously unavailable.
Finding 3 — Retention effect is real at the 90-day mark, attenuates by 12 months
The retention signal is the most commercially relevant finding:
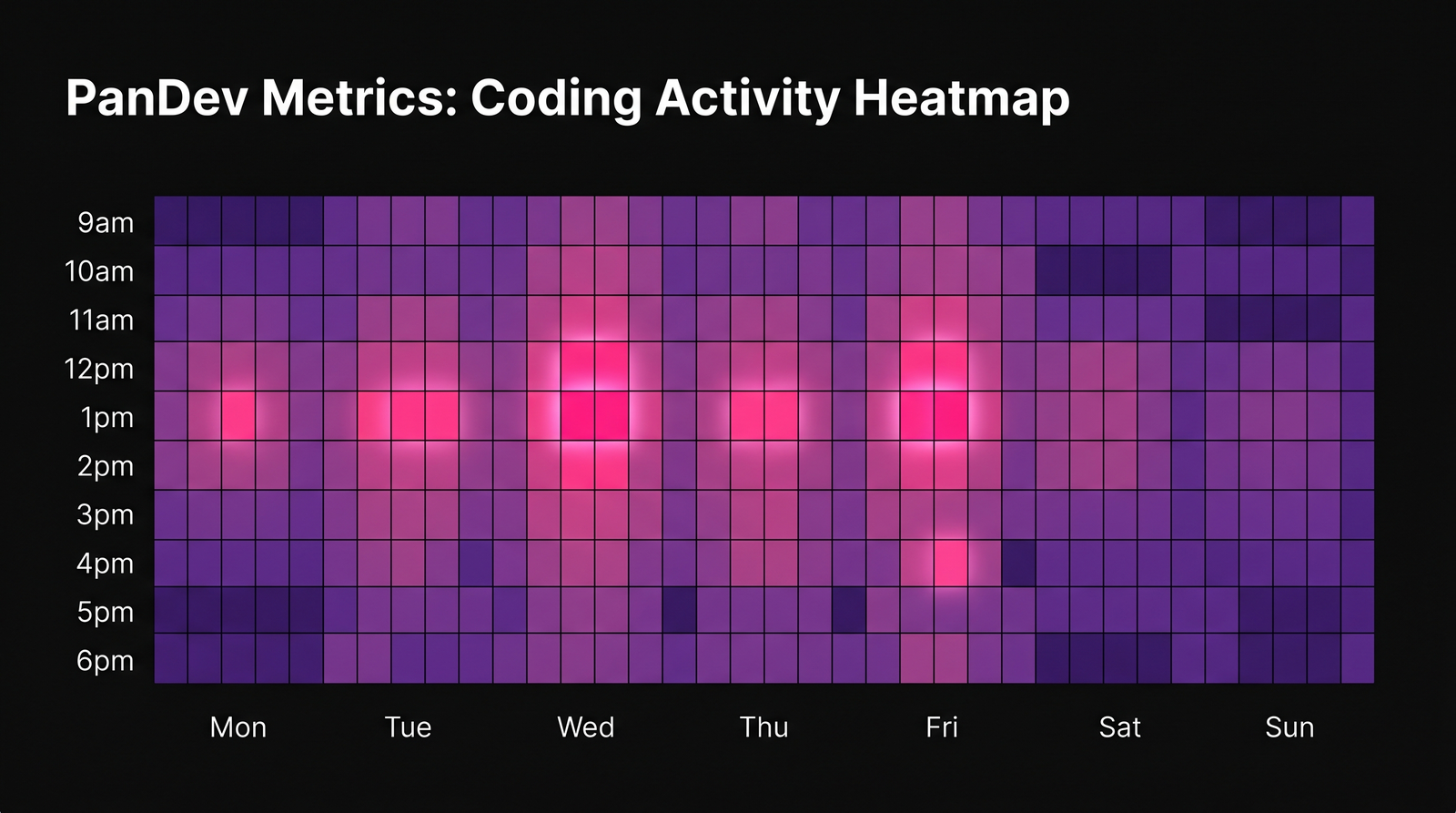 Returning developers' activity pattern rebuilds cleanly: weekday focus blocks in the 11am-2pm band re-emerge first, weekend coding stays close to zero. Pattern matches pre-leave shape by week 3-4.
Returning developers' activity pattern rebuilds cleanly: weekday focus blocks in the 11am-2pm band re-emerge first, weekend coding stays close to zero. Pattern matches pre-leave shape by week 3-4.
| Sabbatical length | 90-day retention post-return | 12-month retention | vs matched cohort (no sabbatical) |
|---|---|---|---|
| 2-3 weeks | 98% | 89% | +3 pp / +2 pp |
| 4-6 weeks | 100% | 92% | +6 pp / +5 pp |
| 7-10 weeks | 98% | 88% | +4 pp / +1 pp |
| 11+ weeks | 92% | 78% | −2 pp / −8 pp |
The 4-6 week band is the sweet spot. Shorter sabbaticals look more like extended vacations — some benefit but limited retention bump. Longer sabbaticals (11+ weeks) show a negative retention effect at 12 months — anecdotally these often become inflection points where the developer uses the time to interview elsewhere.
What this means for engineering leaders
1. Stop budgeting "3 months of lost output" per sabbatical
The conservative budget is 4-6 weeks of ramp-up per taker, with a quality uptick during weeks 2-6 that partially offsets the reduced volume. For a 6-week sabbatical, the effective output loss is ~8-9 weeks, not 16-18 weeks as often assumed.
2. Design the length bracket intentionally
Our data says 4-6 weeks is the optimal sabbatical length for the retention effect. Shorter sabbaticals don't differentiate meaningfully from vacation. Longer ones correlate with higher churn at the 12-month mark.
If the goal is retention: 4-6 weeks every 5-7 years. If the goal is burnout recovery: longer is often needed individually, but you should expect the retention protection to weaken past 10 weeks.
3. Plan return-to-ramp deliberately
Match returning developers to 2-3 smaller, well-scoped tasks in weeks 1-2. This is where the manager's inclination to "ease them in" and the data's signal both align. Developer onboarding research suggests the same ramp pattern for new hires — returning sabbatical-takers aren't new hires, but the first two weeks look structurally similar on the IDE.
4. Track the quality uptick as a team benefit
Teams with sabbatical programs show slightly better week-6-12 quality scores overall — not just from the returning developer, but from the team, because the returning person often picks up reviewer / mentor responsibilities in those weeks. This is a small signal (2-4 percentage-point improvement in team PR-first-review rate) but it's measurable and it's durable.
Methodology
- IDE heartbeat data from the pre-sabbatical 12-week window establishes the individual baseline. Coding time, language distribution, and focus-time patterns are all measured against this baseline (not a team-wide or industry-wide one).
- Sabbatical flag requires explicit product-side tagging — formal sabbatical policies only, not ambiguous "extended PTO."
- Matched control cohort for retention analysis: engineers of similar tenure, role, and pre-leave activity who did not take sabbaticals in the same year. Matching is not randomized; some residual confounding likely.
- Quality proxies (PR-first-review rate, revert rate) are imperfect — they reflect workload characteristics as well as true quality. We report them as suggestive, not conclusive.
The contrarian take
The standard HR case for sabbaticals is "it helps with burnout." Our data doesn't refute that, but it points somewhere else: the measurable benefit is on code quality during ramp-up weeks, not on long-term individual productivity. Developers come back at roughly the same output level they left. What changes is how they work for 4-8 weeks — smaller PRs, cleaner commits, more mentorship volunteering. The business case for sabbaticals is less about the individual taking the break and more about the 2-month window of elevated team health that follows.
The corollary is uncomfortable: if you don't have the team in place to absorb the output gap for 4-6 weeks, the sabbatical doesn't generate these benefits — it just shifts the workload to colleagues, who then are the ones burning out. Sabbaticals without adequate bench depth are vanity policies.
The honest limit
Our 47-developer sample is too small for strong claims at the level of specific percentage points. The observation windows are too short to say anything about 3-5 year retention effects (which is the business horizon some HR leaders care about most). We don't have signal on non-engineering roles taking sabbaticals from the same companies — the team effect may or may not generalize beyond engineering. The quality-uptick finding (Finding 2) is the most fragile — returning developers get easier work, so we can't cleanly separate rest effect from task effect.
Taking this data to a board discussion as "proof that sabbaticals are a retention tool" would be overclaiming. Taking it as "directional evidence that 4-6 week sabbaticals every 5-7 years cost less than HR folklore says and produce measurable short-term team benefit" is defensible.
Where PanDev Metrics fits
The dataset behind this post comes from IDE heartbeat telemetry across the PanDev Metrics customer base. The same data supports team-level measurement of any programmatic HR intervention — sabbaticals, extended parental leave, compressed workweek pilots, remote-work policy changes. For leaders piloting a new HR policy, the engineering-intelligence dashboard is the only place where a rigorous before/after measurement is practical without separate instrumentation. We're seeing more customers use this pattern specifically because traditional HR analytics rely on self-report, which is exactly the instrument that over-estimates sabbatical benefit in the published literature.
Related reading
- How Much Developers Actually Code (Real IDE Data from 100+ Teams) — the baseline research that establishes our coding-time benchmarks, referenced throughout this post
- 5 Data Patterns That Scream 'Your Developer Is Burning Out' — the signals that often precede sabbatical requests; useful for HR leaders designing sabbatical policy
- New Developer Onboarding: How Metrics Show the Ramp-Up to Full Productivity — the structurally-similar ramp curve for new hires; returning sabbatical-takers follow a compressed version of this
- External: SHRM 2023 Employee Benefits Survey — the public reference on sabbatical-program adoption rates
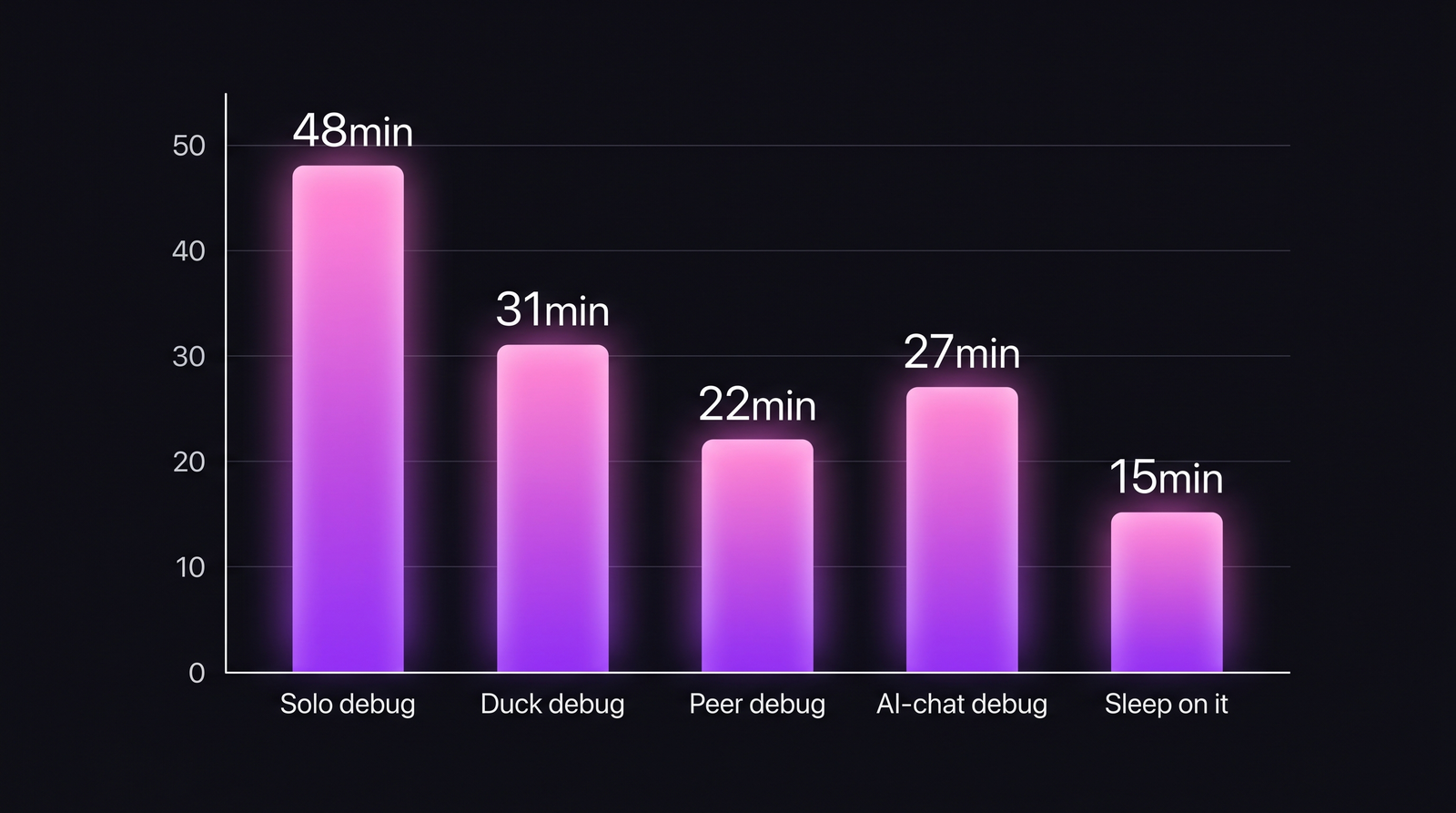 Peer debugging is the gold standard when the peer is available. Rubber duck matches AI-chat debugging closely, because both force verbalization — the technique, not the partner, is what works.
Peer debugging is the gold standard when the peer is available. Rubber duck matches AI-chat debugging closely, because both force verbalization — the technique, not the partner, is what works.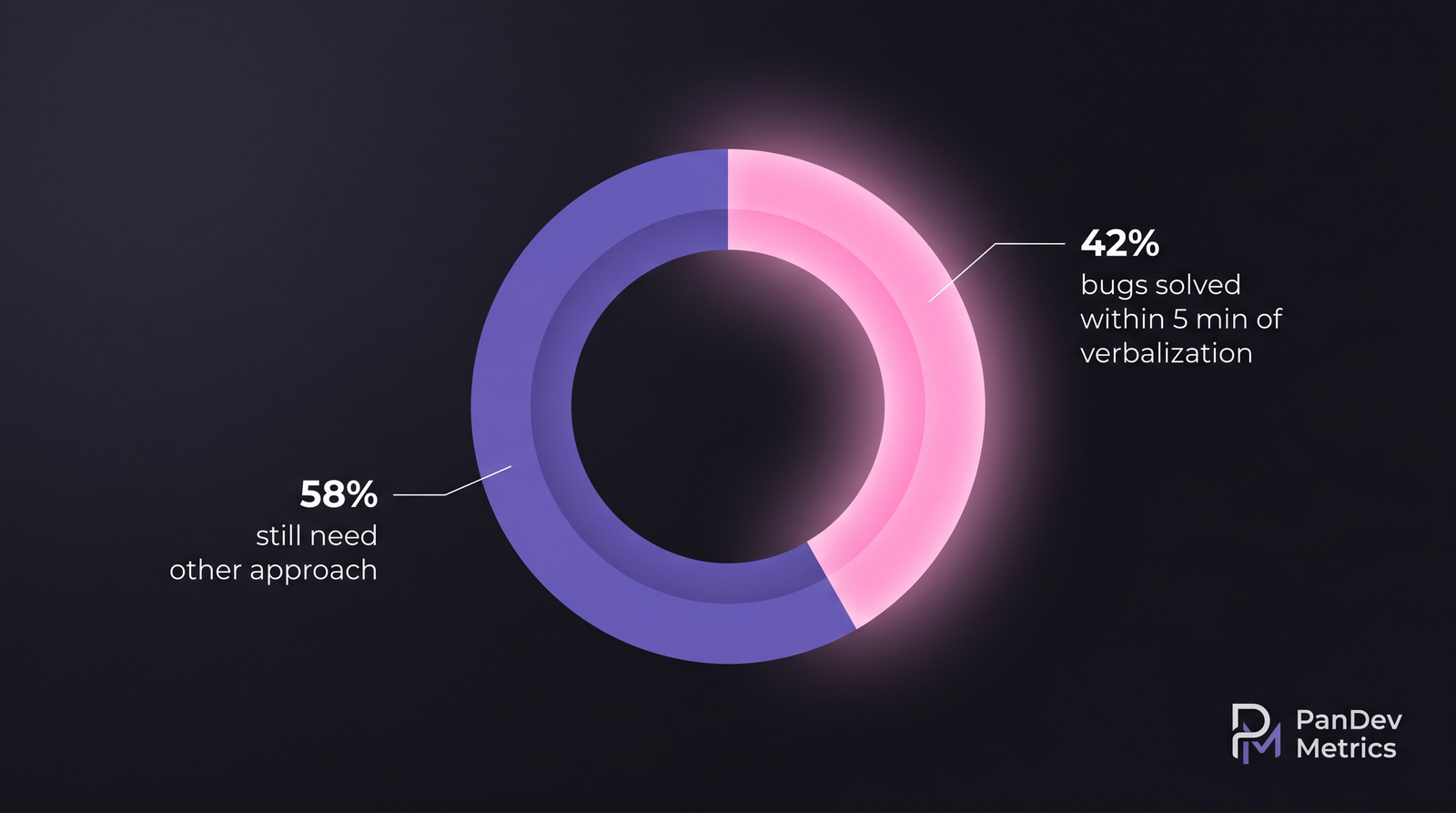 Aggregate: 42% of bugs get solved within 5 minutes of starting verbal explanation. The other 58% need different approaches — profiling, traces, a long break, or a peer who knows the system.
Aggregate: 42% of bugs get solved within 5 minutes of starting verbal explanation. The other 58% need different approaches — profiling, traces, a long break, or a peer who knows the system.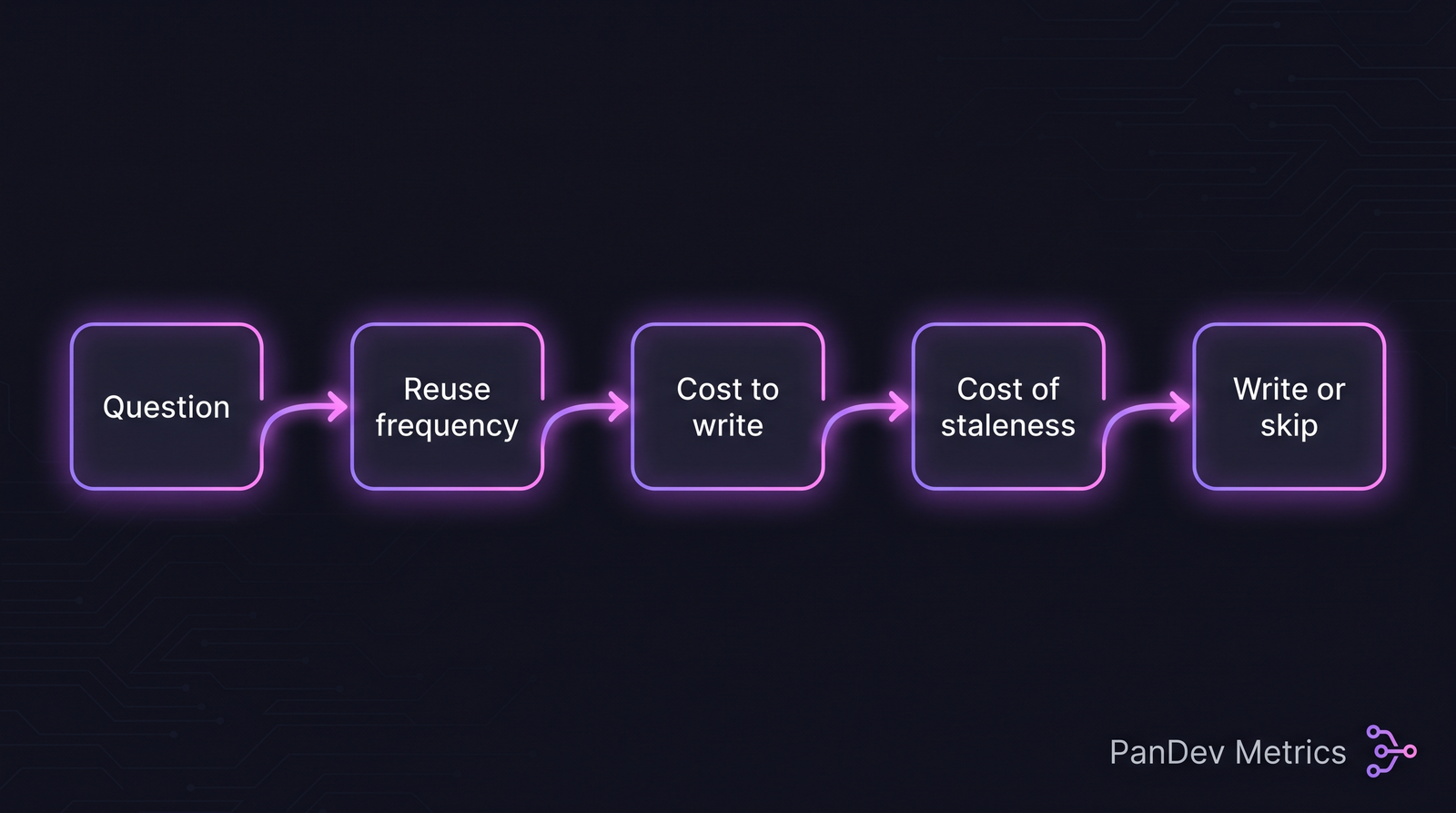 The five-step decision. Most "should we write this?" arguments skip step 3 (cost to write) and step 4 (cost of staleness).
The five-step decision. Most "should we write this?" arguments skip step 3 (cost to write) and step 4 (cost of staleness).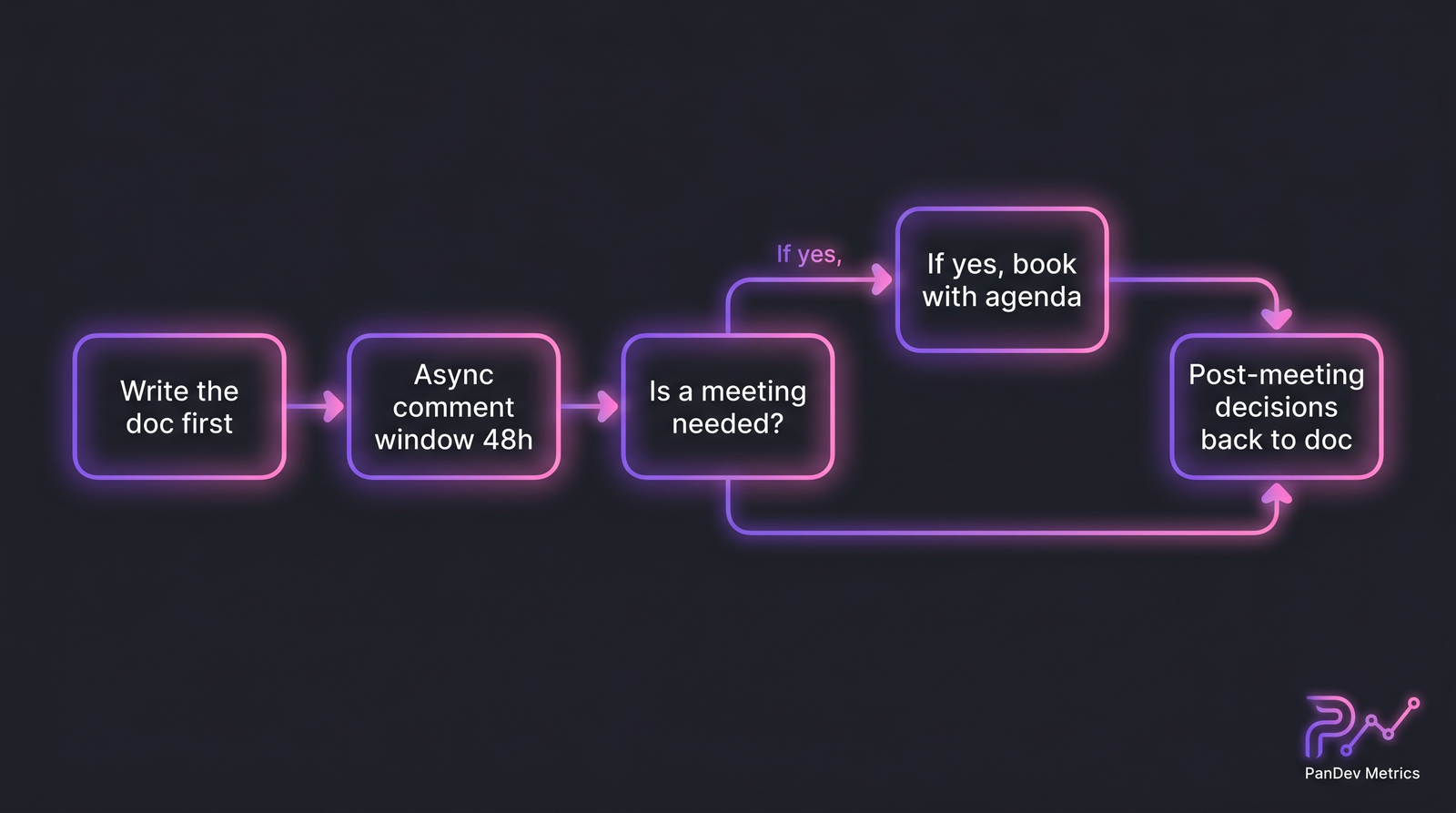 The async-first decision loop. Most proposed meetings die at the "is this meeting needed?" question once the 48h async window closes.
The async-first decision loop. Most proposed meetings die at the "is this meeting needed?" question once the 48h async window closes. The 7 steps that separate offsites with measurable ROI from offsites that read as culture-only.
The 7 steps that separate offsites with measurable ROI from offsites that read as culture-only.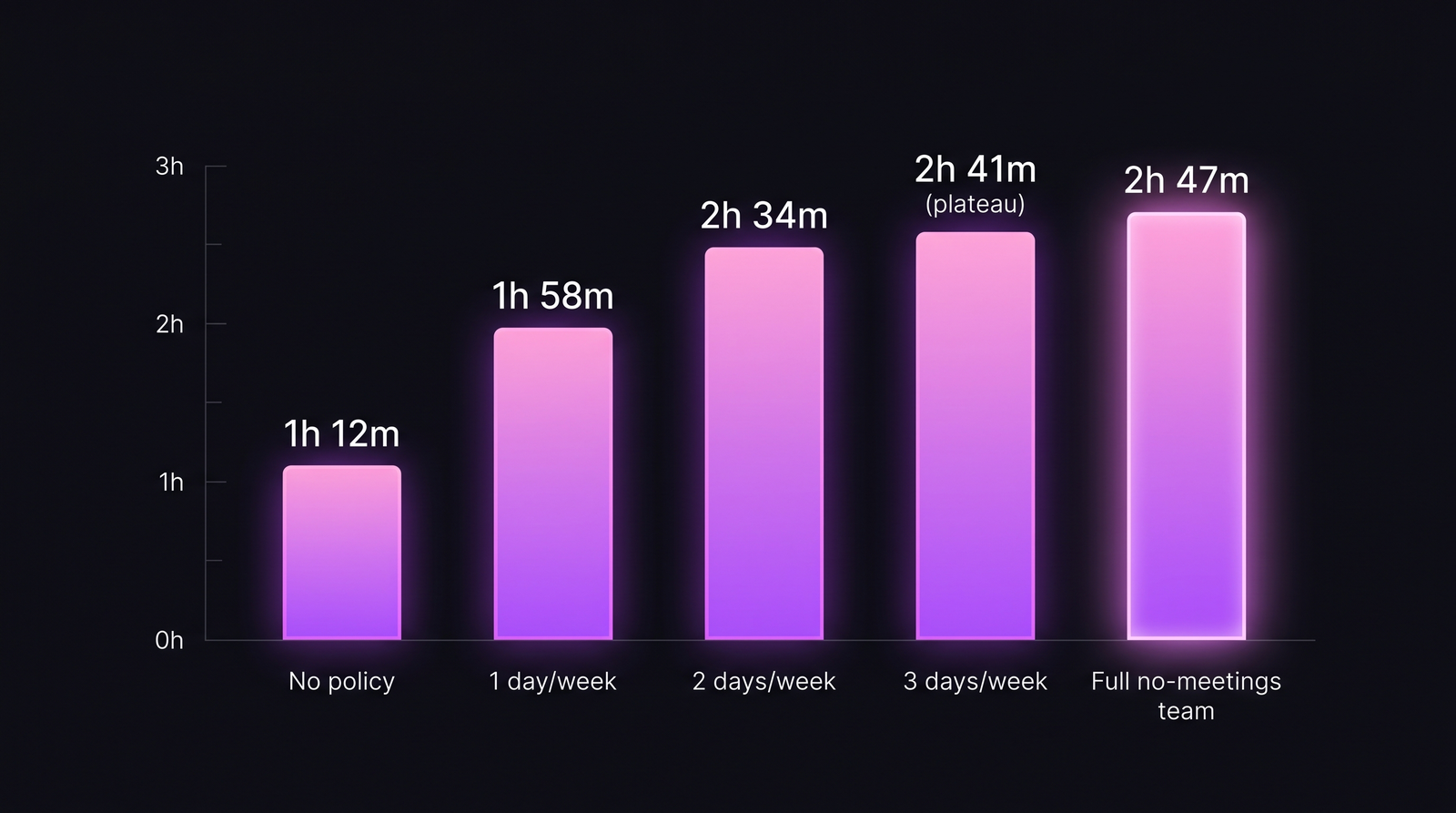 The curve flattens at 2 meeting-free days per week. The third day produces almost no additional coding time.
The curve flattens at 2 meeting-free days per week. The third day produces almost no additional coding time. Before: focus fragments across every weekday. After: two concentrated "deep work" days emerge.
Before: focus fragments across every weekday. After: two concentrated "deep work" days emerge.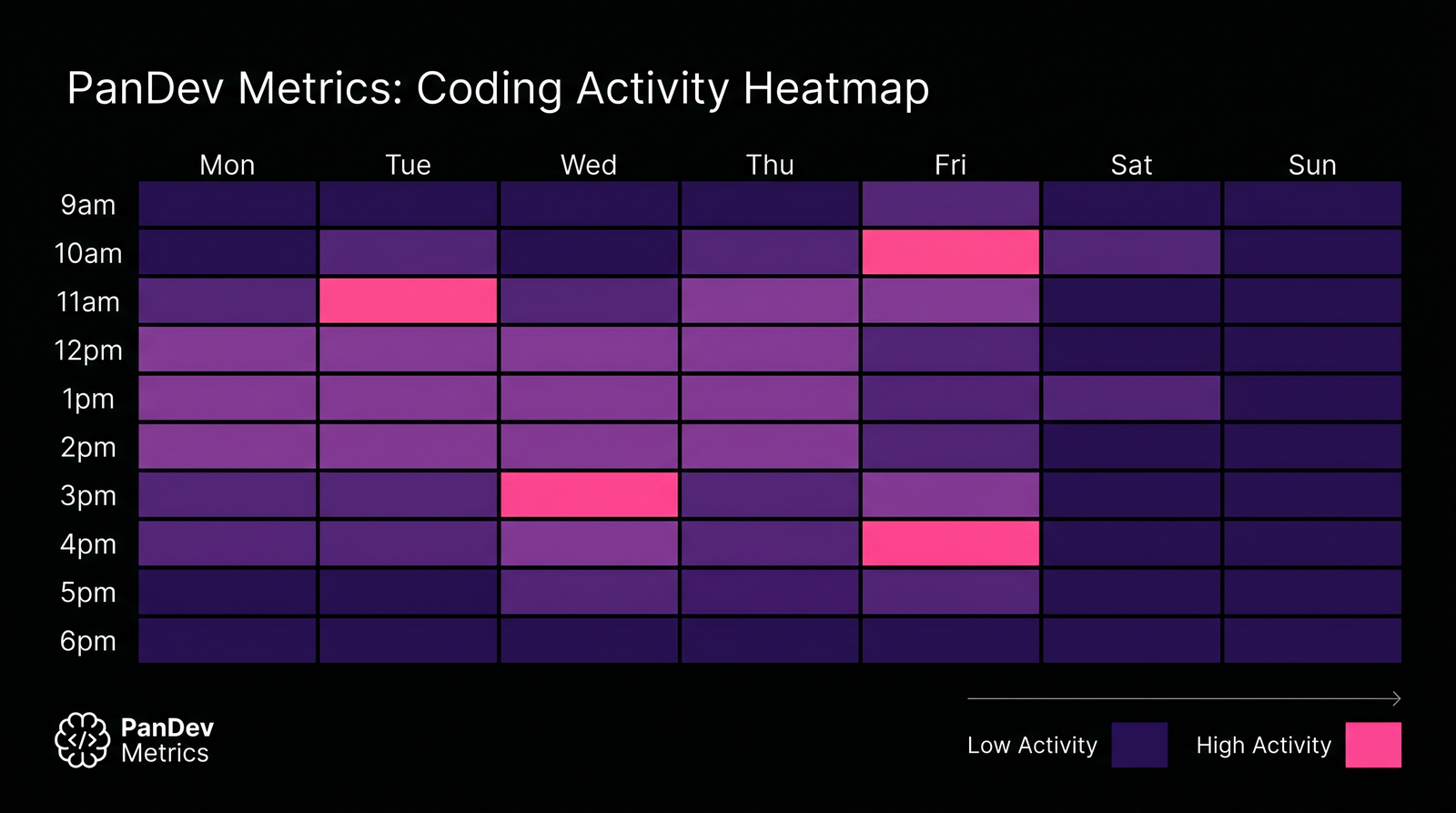 The shape that works: mornings are yours, afternoons are the team's, Friday is for shipping.
The shape that works: mornings are yours, afternoons are the team's, Friday is for shipping.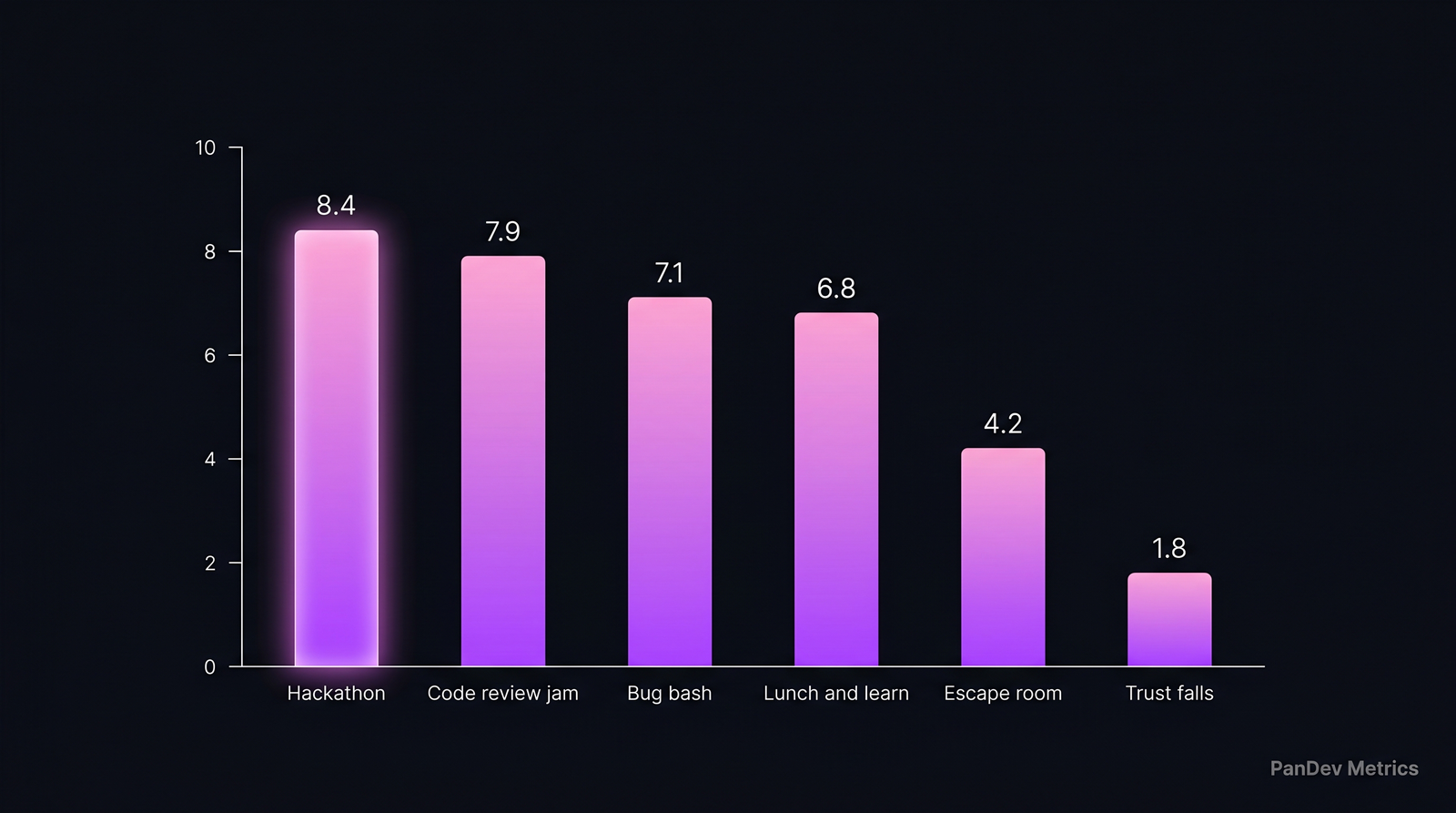 The pattern: activities adjacent to the work score highest. Activities chosen to "not feel like work" score lowest. A hackathon is more social than trust falls — the social is a byproduct of doing something engineers respect.
The pattern: activities adjacent to the work score highest. Activities chosen to "not feel like work" score lowest. A hackathon is more social than trust falls — the social is a byproduct of doing something engineers respect.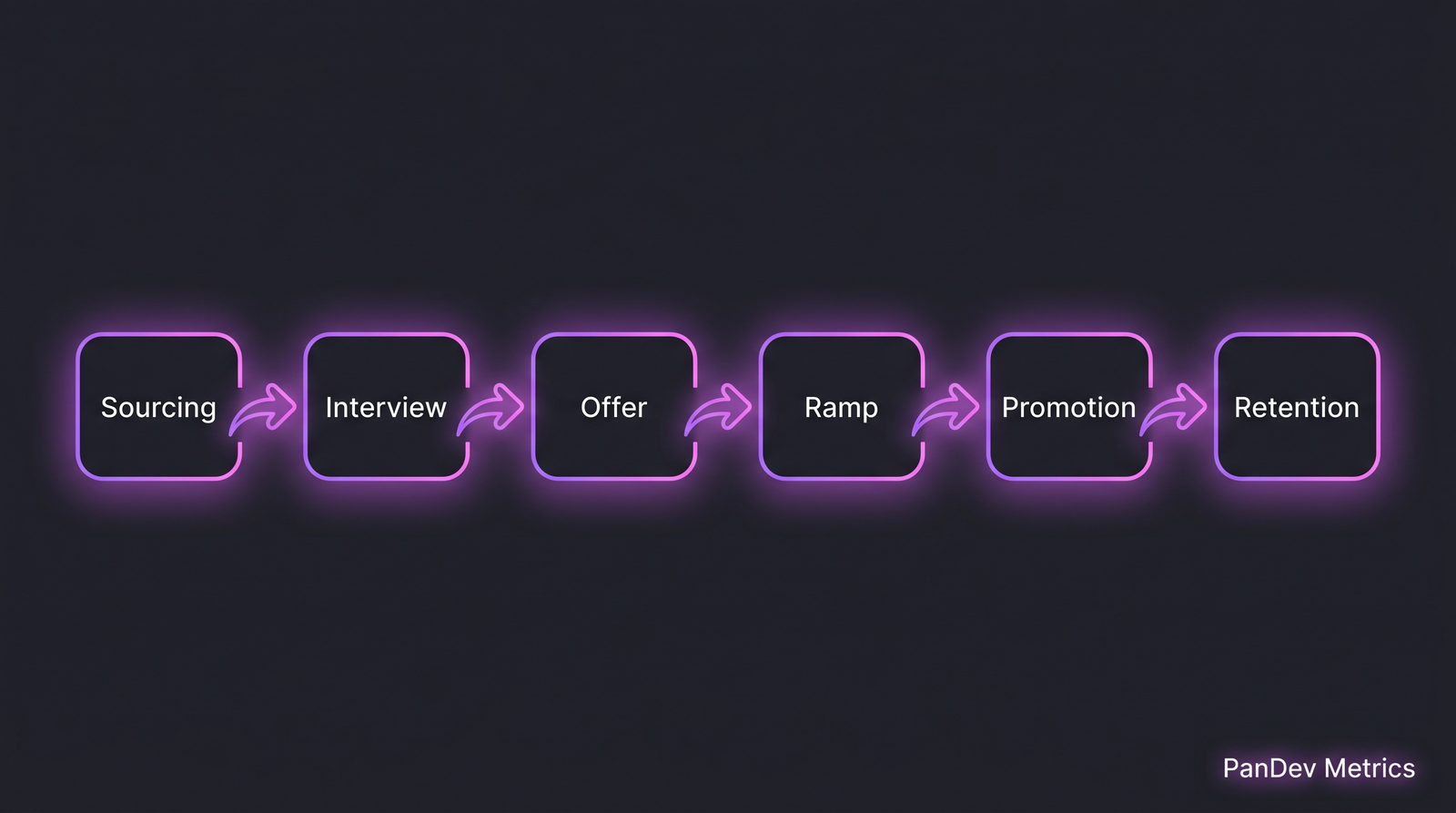 Six stages, each a filter. Hiring numbers measure the first three. Culture lives in the last three.
Six stages, each a filter. Hiring numbers measure the first three. Culture lives in the last three.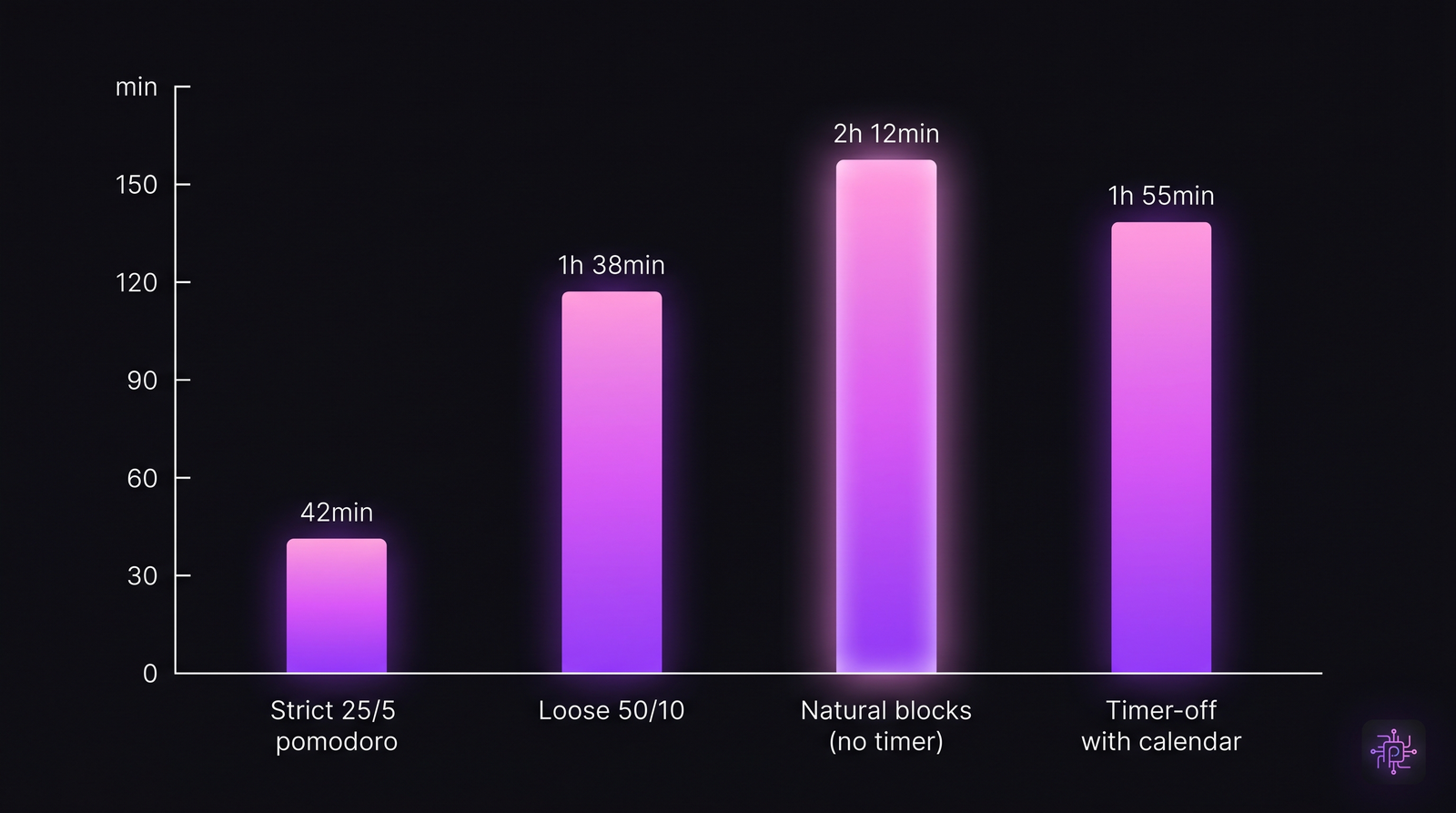 Daily active coding time by focus technique. Strict 25/5 Pomodoro users show the lowest totals, not because they're lazy — because 25-minute intervals chop coding sessions before flow consolidates.
Daily active coding time by focus technique. Strict 25/5 Pomodoro users show the lowest totals, not because they're lazy — because 25-minute intervals chop coding sessions before flow consolidates. Weekly coding-activity distribution. The darker bands are the coding peaks; note how they cluster at specific hours for most engineers, and how Pomodoro's rhythm doesn't match them.
Weekly coding-activity distribution. The darker bands are the coding peaks; note how they cluster at specific hours for most engineers, and how Pomodoro's rhythm doesn't match them.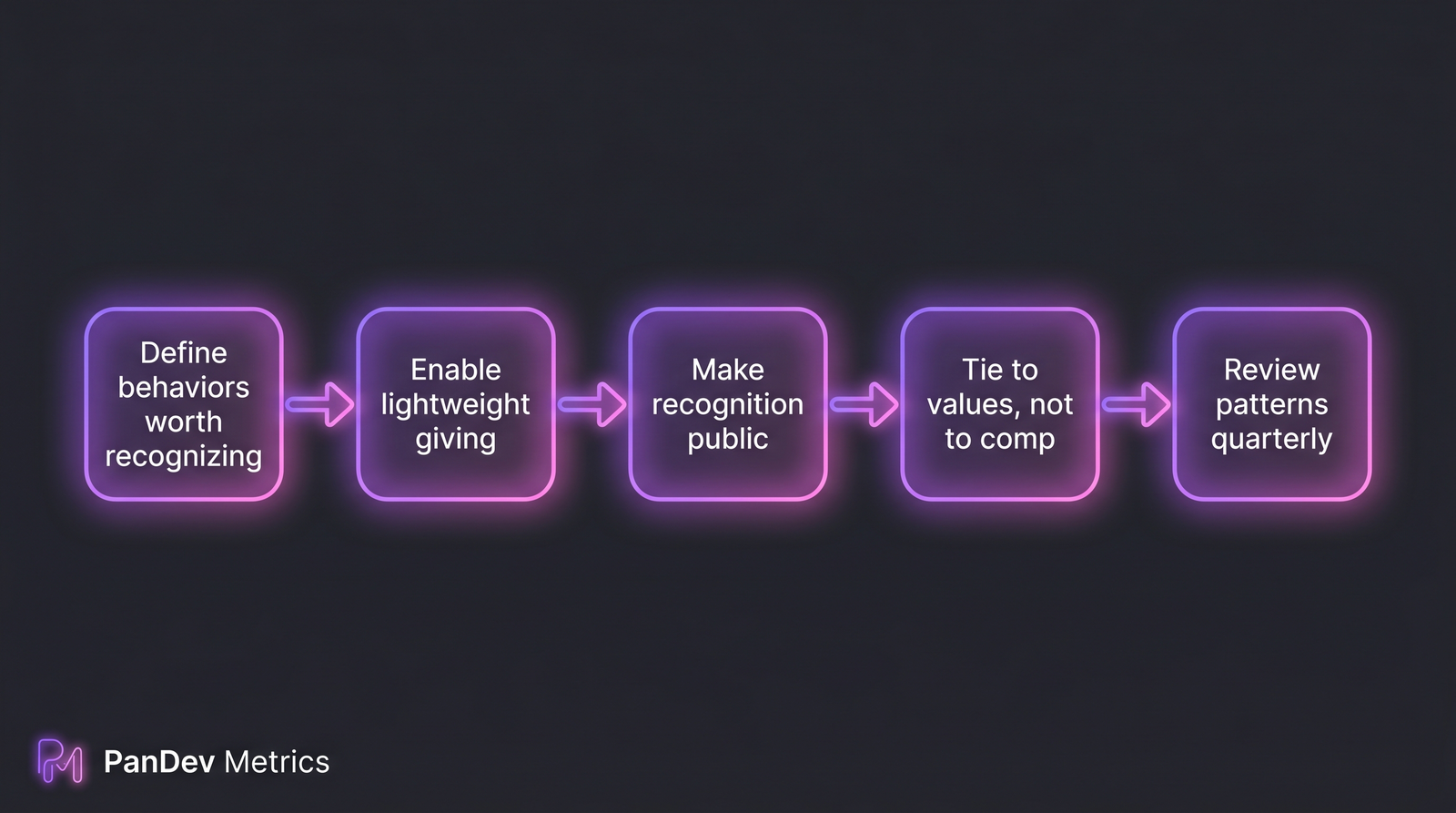 The 5-step recognition loop. Each step has a common failure mode that kills the system if skipped.
The 5-step recognition loop. Each step has a common failure mode that kills the system if skipped.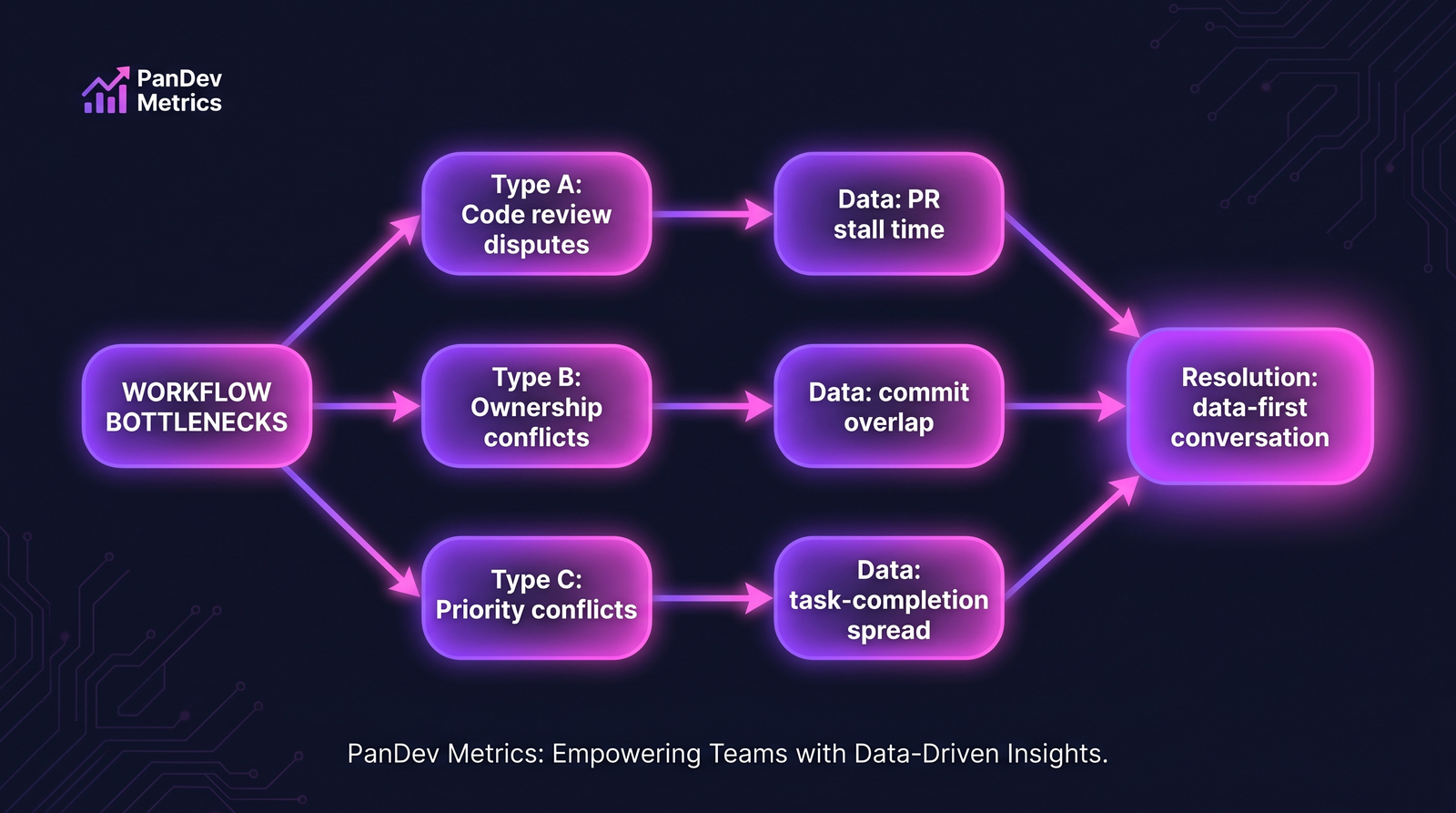 The four common conflict types. Each has a distinct data signature in Git/PR/IDE activity.
The four common conflict types. Each has a distinct data signature in Git/PR/IDE activity.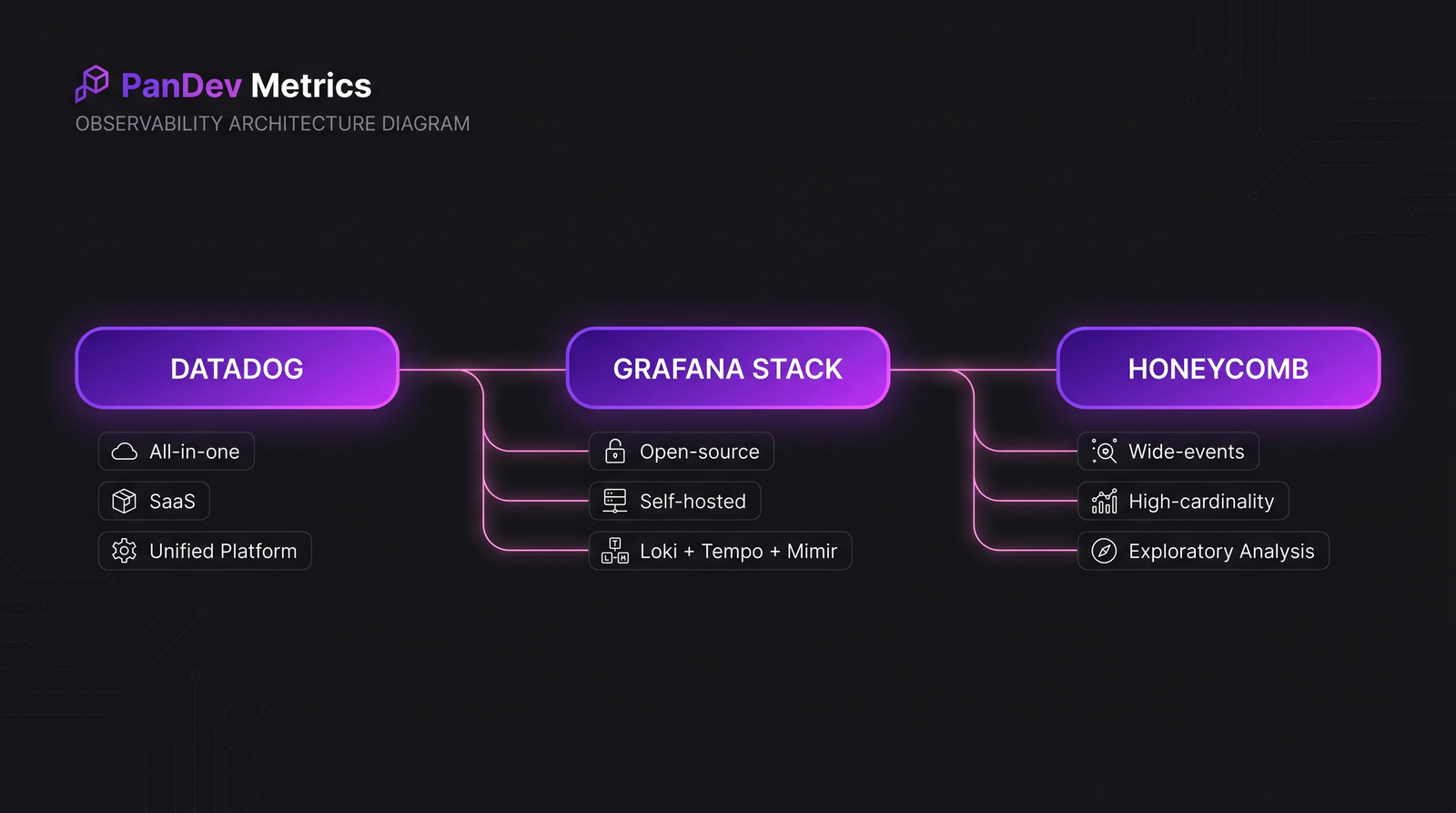 The three tools aren't direct substitutes. Picking one against the others is usually picking which failure mode you can afford to have.
The three tools aren't direct substitutes. Picking one against the others is usually picking which failure mode you can afford to have.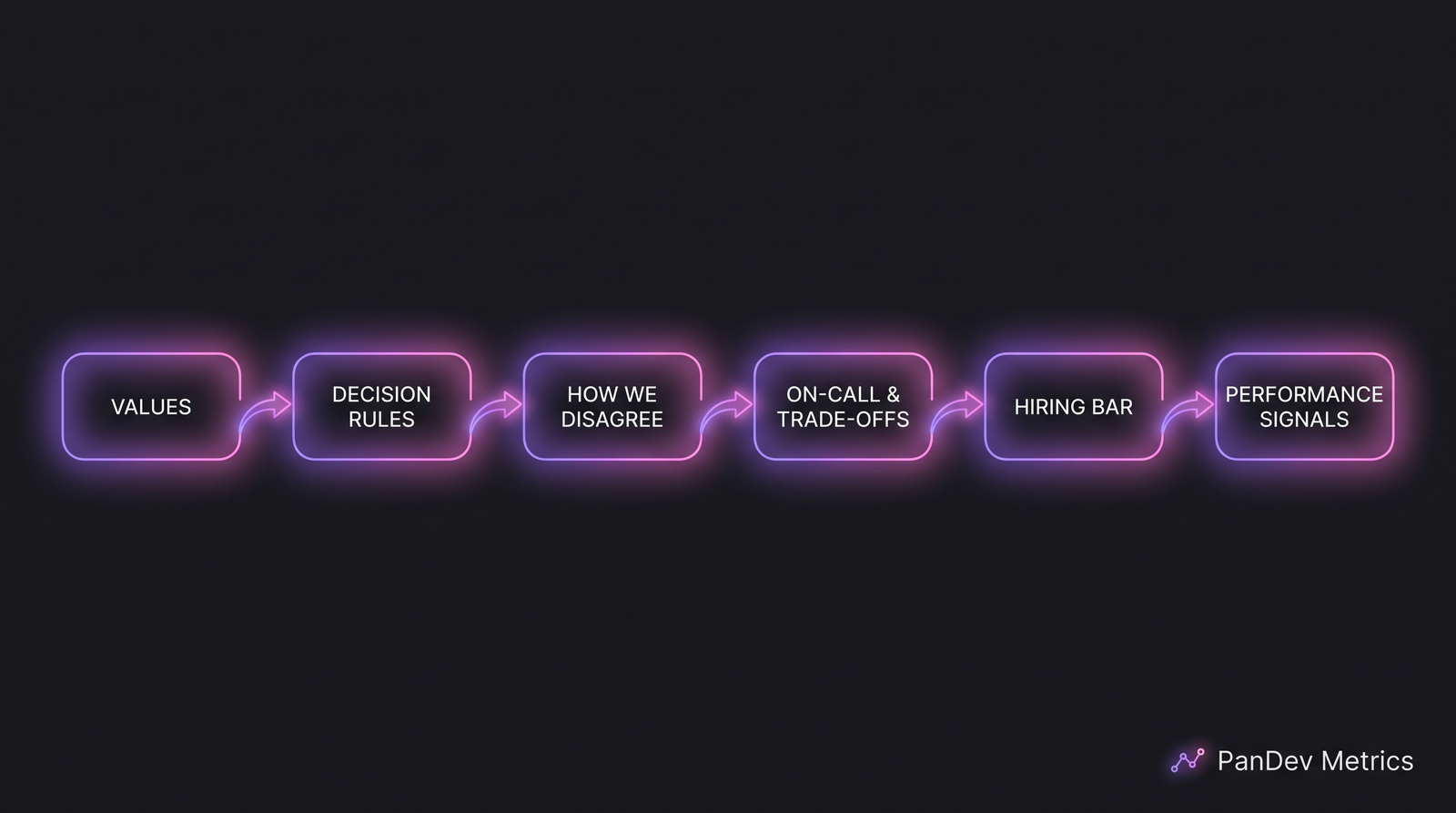 Culture is an operating system for decisions. These six sections together produce the boot sequence.
Culture is an operating system for decisions. These six sections together produce the boot sequence.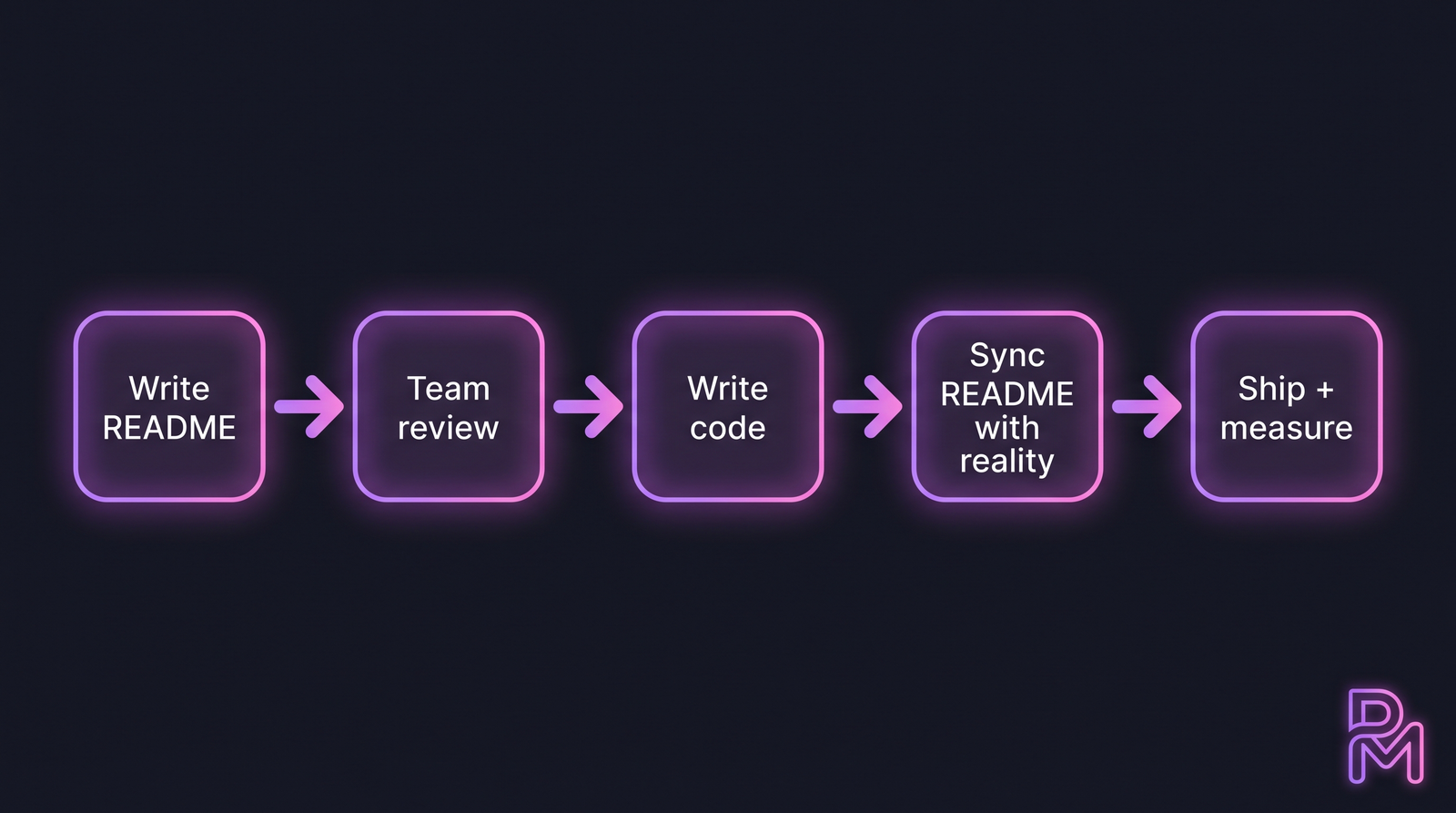 The README is the contract. Code implements the contract. The gate from step 3 to step 4 is what most teams skip — syncing the README when reality diverges.
The README is the contract. Code implements the contract. The gate from step 3 to step 4 is what most teams skip — syncing the README when reality diverges.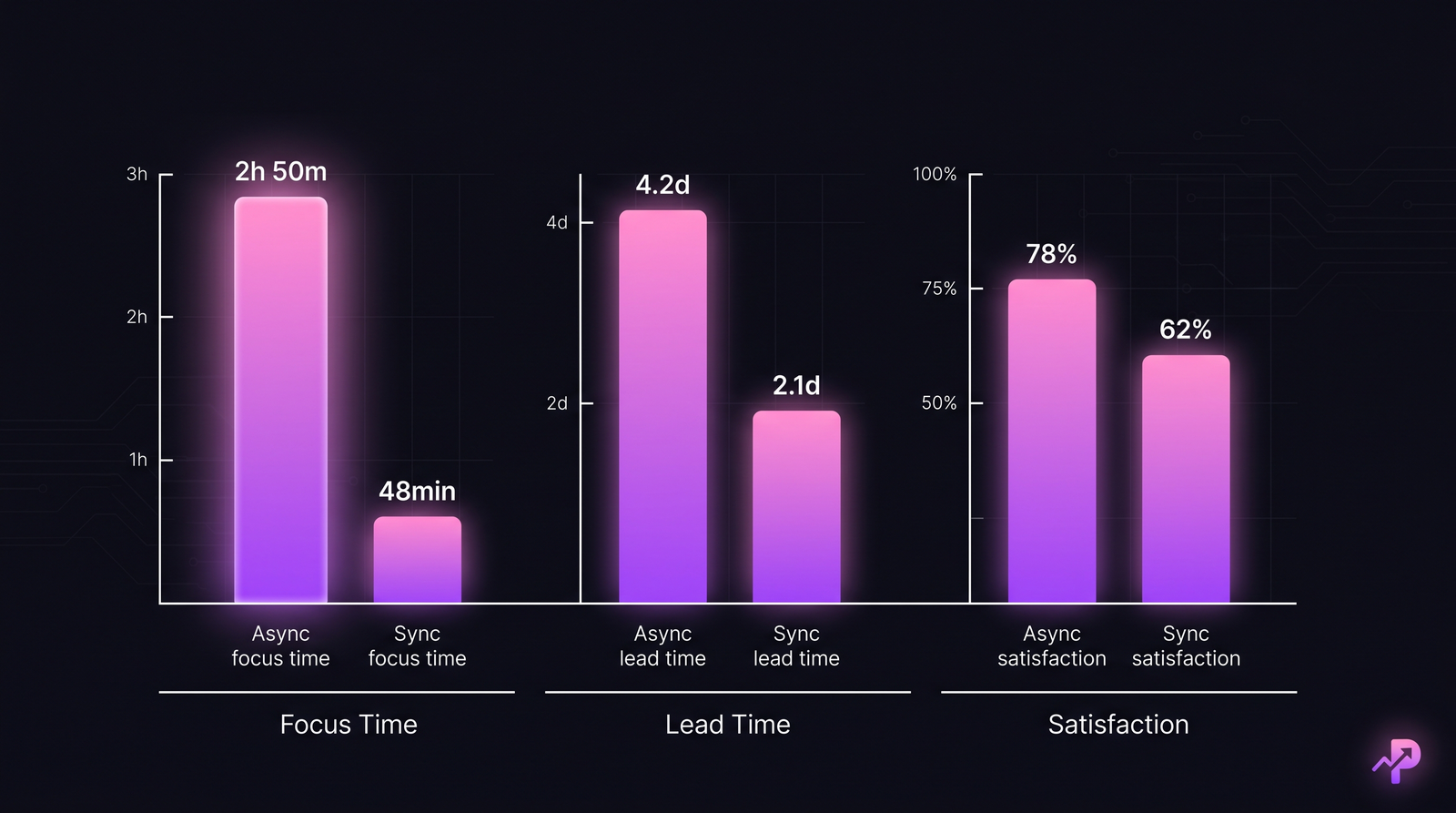 Three axes that move in different directions under async vs sync. Focus time and satisfaction go up async; decision speed goes up sync. The satisfaction numbers above are from our customer segment and shouldn't be read as industry-wide.
Three axes that move in different directions under async vs sync. Focus time and satisfaction go up async; decision speed goes up sync. The satisfaction numbers above are from our customer segment and shouldn't be read as industry-wide.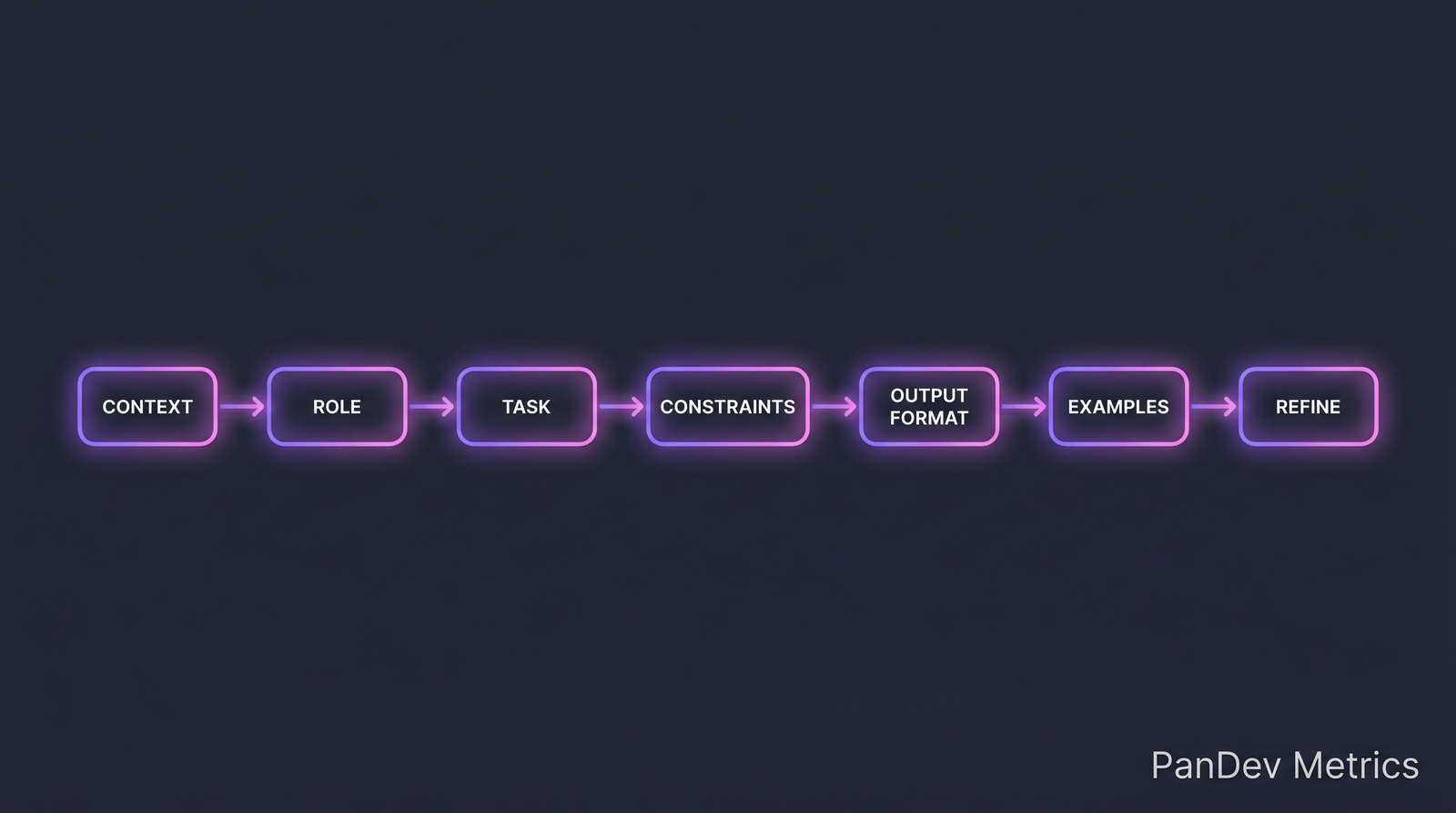 The seven-part prompt structure that works for code generation. Teams converge on variations of this.
The seven-part prompt structure that works for code generation. Teams converge on variations of this.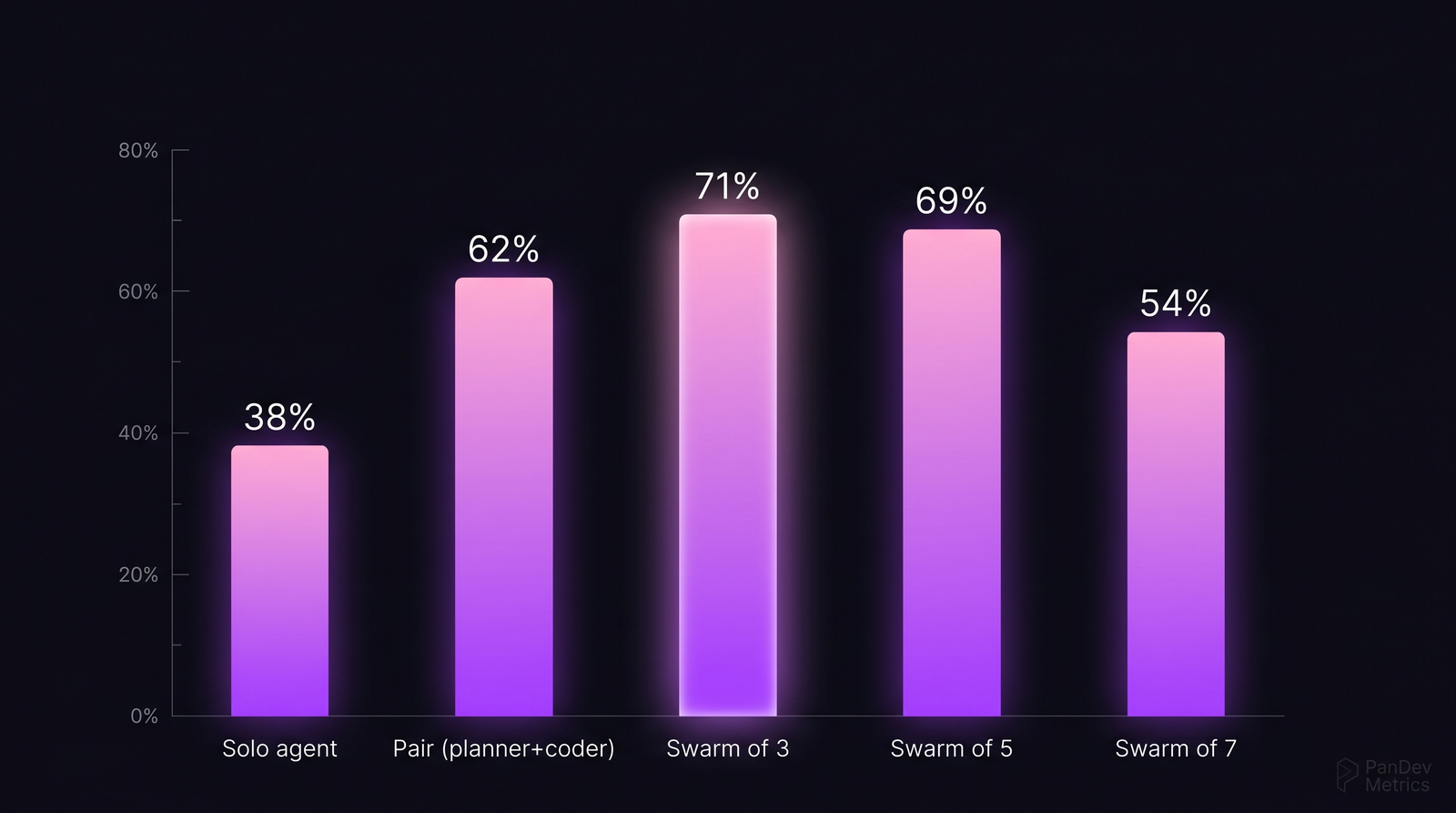 Task success rate by agent swarm size. The peak at 3 agents and the decline past 5 replicates across SWE-Bench, MetaGPT evals, and CrewAI harness runs. Source: aggregated from four 2024-2025 benchmarks.
Task success rate by agent swarm size. The peak at 3 agents and the decline past 5 replicates across SWE-Bench, MetaGPT evals, and CrewAI harness runs. Source: aggregated from four 2024-2025 benchmarks.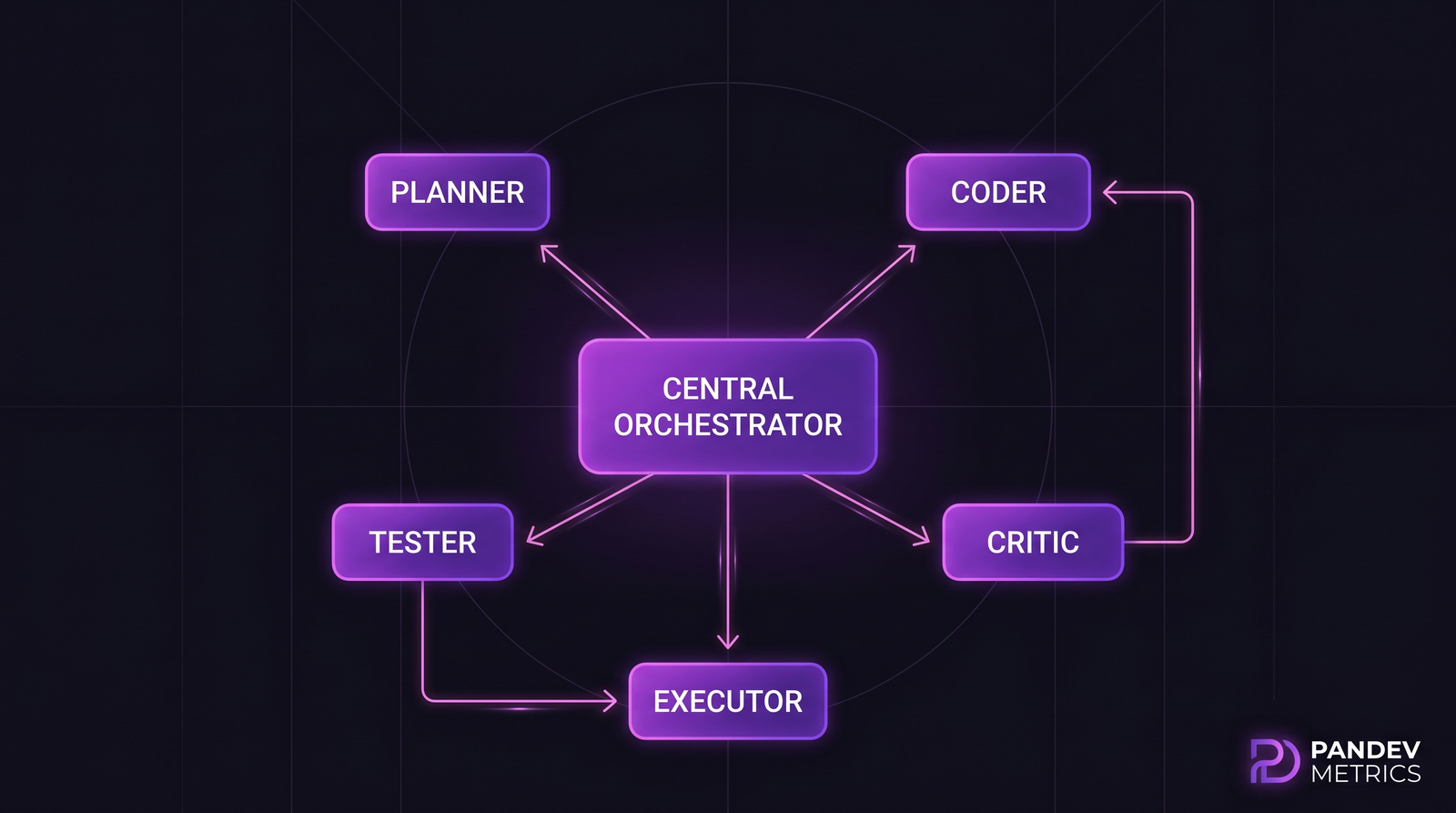 The 5-agent extension adds separate Tester and Executor roles. Benchmark data shows marginal improvement over 3-agent, but doubles token cost.
The 5-agent extension adds separate Tester and Executor roles. Benchmark data shows marginal improvement over 3-agent, but doubles token cost.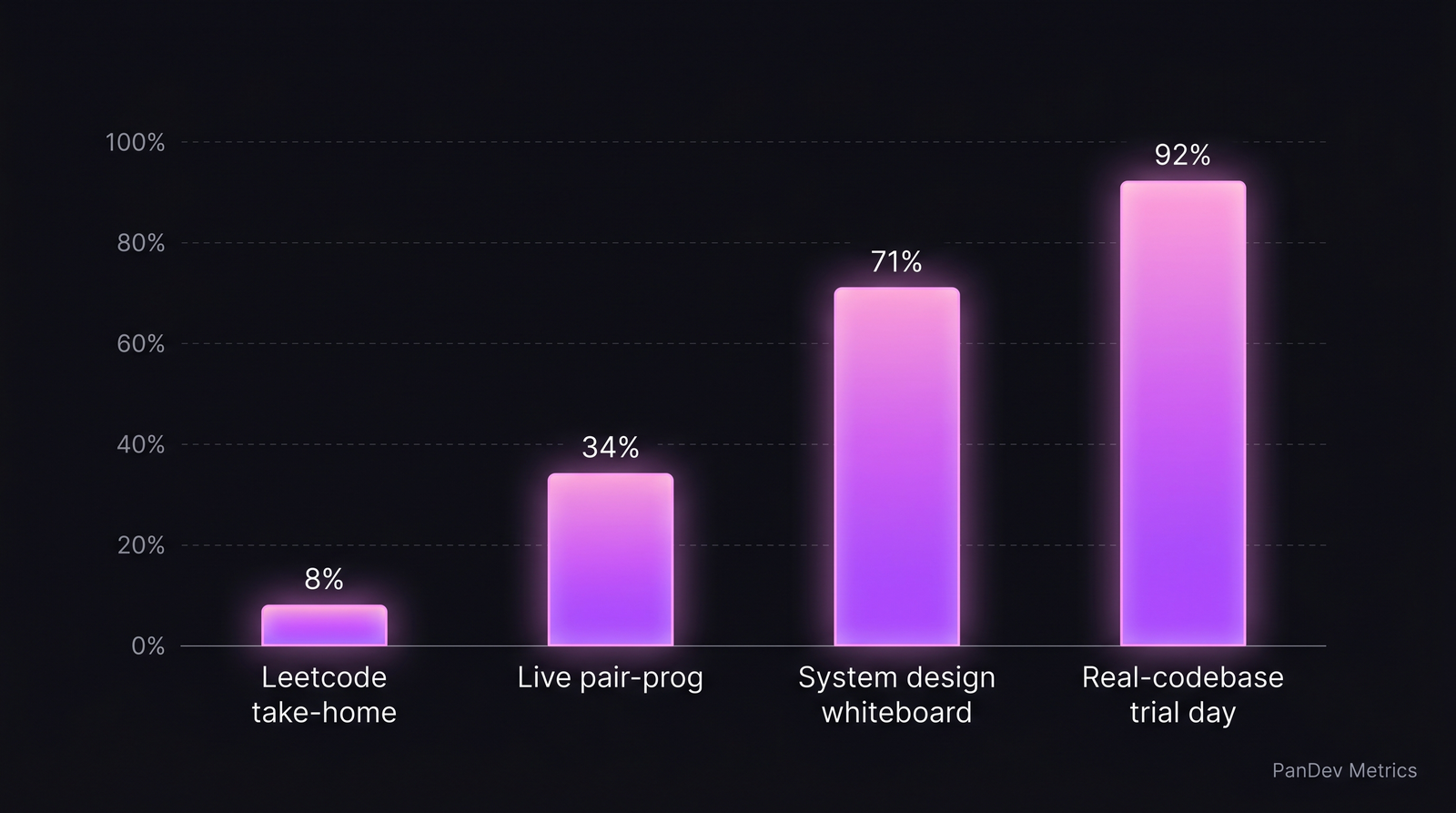 Signal-to-cheat ratio across interview formats. Take-homes are the worst; real-codebase trial days the best.
Signal-to-cheat ratio across interview formats. Take-homes are the worst; real-codebase trial days the best.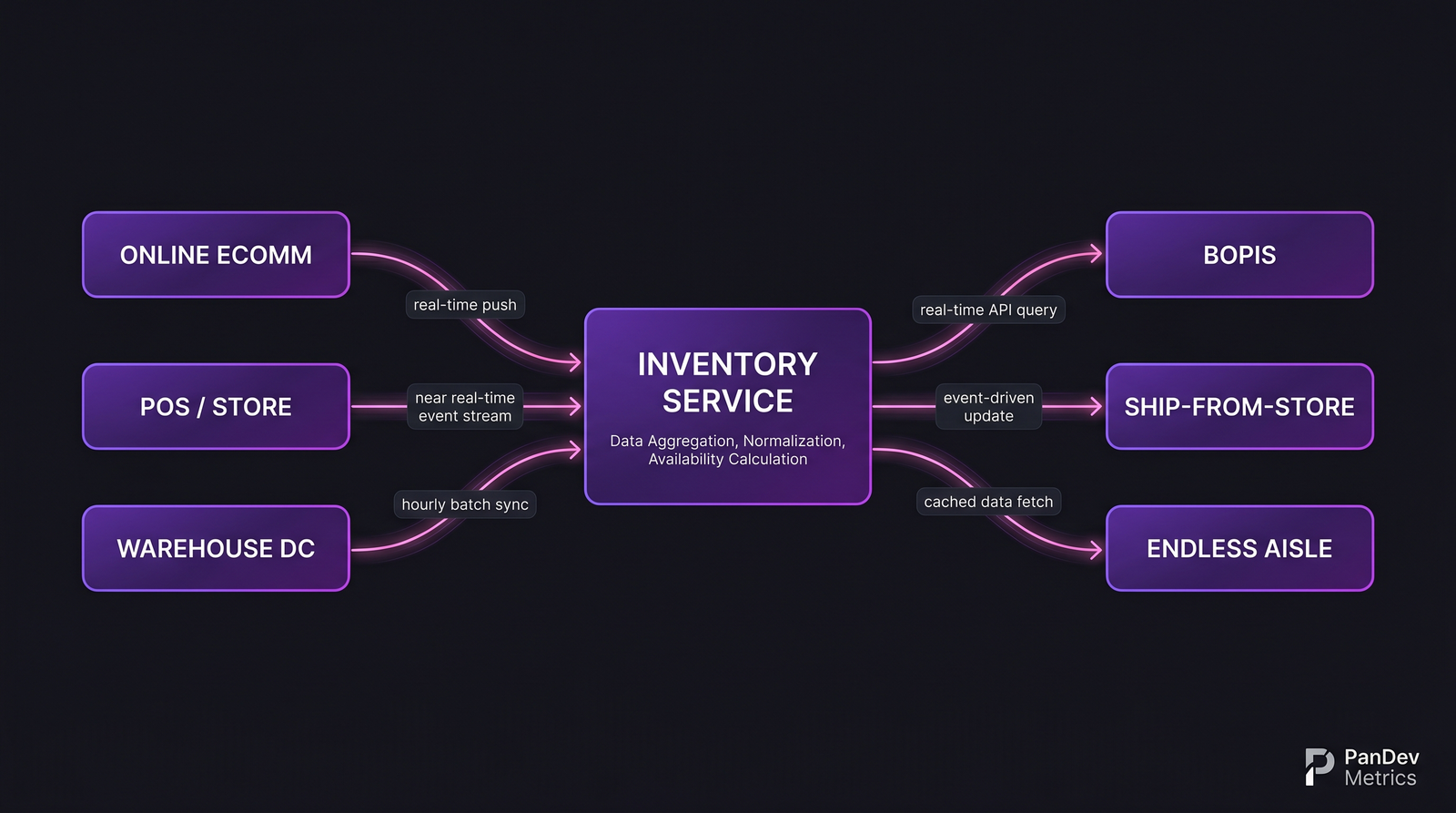 The inventory service is the keystone. Every omnichannel feature depends on it, and every feature shipped without considering its impact on inventory freshness creates debt that compounds through the next peak season.
The inventory service is the keystone. Every omnichannel feature depends on it, and every feature shipped without considering its impact on inventory freshness creates debt that compounds through the next peak season.